What is an ontology?
The idea is not new and can be traced back to Aristotle, but in computer science, an ontology is a formal description of how we conceptualize a domain. In other words, it answers these three questions:
- What kinds of entities exist?
- What relationships between them are allowed?
- What rules and constraints must always be true?
You can encode an ontology into JSON, embed it in a prompt, express it as a SQL schema, or store it in an RDF triplestore. The format is secondary. The meaning is what counts.
Ontologies matter for AI because:
- Constrained extraction limits the entity types and relationships that an LLM can extract.
- An interoperable structure provides a shared format for knowledge representation (standards matter).
- Deterministic reasoning enables rule-based inference using mature, well-tested tooling.
- Meaning preservation, as without ontology, the context erodes. Systems, remember what happened, but lose why it was valid.
An ontology doesn’t store raw data. It defines what that data means.
Why LLMs need ontologies:
LLMs are statistical pattern matchers. Ontologies introduce logical structure. When you combine them, something powerful emerges.
Without an ontology, an LLM might accept:

With a medical ontology:

The ontology doesn't just store facts. It defines what kinds of facts are possible. The numbers back it up.
- FalkorDB experienced 90% reduction in hallucinations compared to traditional RAG with ontology;
- LinkedIn reached 63% improvement in support ticket resolution (40h → 15h) using this approach;
- OntoGPT + SNOMED CT had 98% accuracy in medical term mapping vs 3% without grounding using ontology.
Google’s Knowledge Graph has applied these ideas since 2012 and now answers roughly a third of its 100 billion monthly searches directly from structured knowledge. Amazon’s product ontology reportedly boosts recommendation accuracy by 60%.
This isn’t hype, it’s infrastructure that has quietly powered production systems for over a decade.
Core ontology concepts
To use ontologies effectively, you need to understand the foundations.
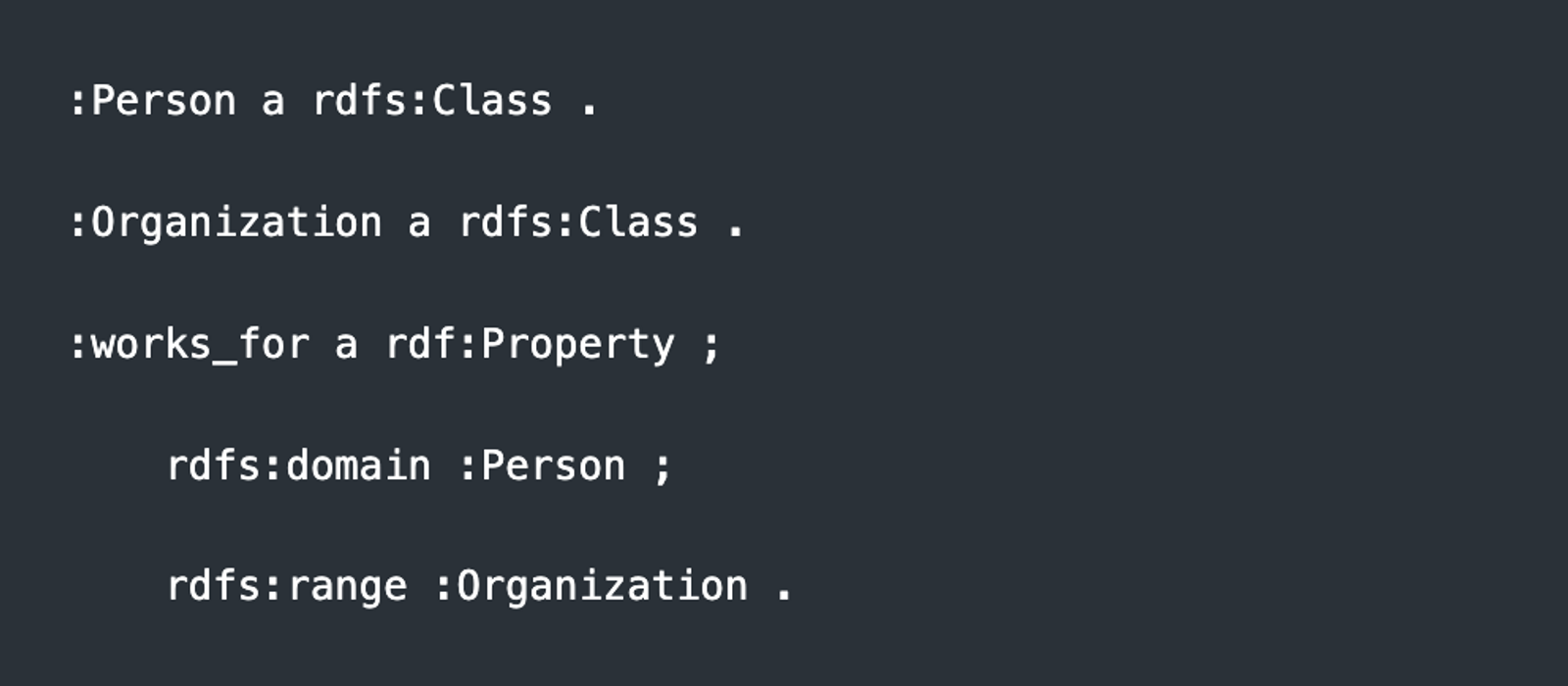
RDF triples - the smallest unit of knowledge.
RDF (Resource Description Framework) represents data as triples: Subject, Predicate, Object.
Each triple makes a statement about the world:

Components:
Subject - the entity being described (Alice)
Predicate - the relationship or attribute (works_for)
Object - the value or related entity (Acme_Corp, Python)
Triples are like LEGO bricks for knowledge. From simple profiles to NASA-scale datasets, everything is built from these atomic statements.
Why triples?
Flexible, add new facts without altering schema;
Naturally connected, relationships are first-class;
Machine-readable, semantics are explicit.
What do the standards provide
RDFs define types and constraints:
- A Person can work_for an Organization — not the other way around.
OWL introduces logical inference:
- If X is a CEO, then X is automatically both an Employee and a Person.

SPARQL enables querying:
- Find all people working for companies located in San Francisco.

Domain ontologies already exist
In many industries, ontologies are already mature and standardized.
Healthcare:
SNOMED CT, 350,000+ clinical terms;
Gene Ontology (GO), biological processes and molecular functions;
ICD-10, WHO disease classification;
FHIR, healthcare data interoperability.
Finance:
FIBO (Financial Industry Business Ontology), collaboration between EDMC and OMG;
Fraud detection models ontologies;
Regulatory compliance frameworks.
Legal:
LKIF (Legal Knowledge Interchange Format), 200+ structured legal concepts;
Akoma Ntoso, legislative document standard.
If you’re building in healthcare, finance, or legal tech, definitions for “patient,” “transaction,” or “liability” already exist. You don’t have to start from scratch.
W3C standards
These standards have been around 15–25 years, and remain largely unchanged because they work:
RDF (1999) — triple-based data representation
RDFS (2004) — classes and constraints
OWL (2009) — logical reasoning
SPARQL (2008) — graph query language
SHACL (2017) — validation rules
When Google launched Knowledge Graph in 2012, it relied on RDF and OWL. When you implement GraphRAG in 2025, those same foundations are still underneath.
Frankly, it's not easy!
Ontology-based systems aren’t trivial.
Compute costs are real. Reasoning over knowledge graphs is expensive. Constructing them with LLMs requires serious resources.
Scaling is complex. Graph databases don’t shard easily. Splitting relationships across servers is inherently difficult.
Design requires expertise. You need domain understanding. You’ll constantly balance expressiveness and complexity. And ontologies evolve, thus they require maintenance.
The market learned this the hard way. Some companies dismissed knowledge graphs during the initial LLM boom. Then they ran into hallucinations, bias, compliance gaps, and liability risk, and suddenly ontology-based approaches became urgent again.
So what should you do?
You may not need a bigger model. You may need structure.
Start small:
Define the entities in your domain;
Define the valid relationships;
Define the rules that must always hold.
That’s already an ontology, and it already adds value.
Unlike models, which depreciate in value, a well-designed ontology compounds in value over time. It isn’t technical debt. It’s infrastructure.