What is Mastra?
AI software development has matured quickly, but building reliable AI-powered systems is still a complex task.
For this task, most teams end up combining several tools such as LLM APIs, orchestration layers, vector databases, and custom backend logic. While the combination approach works, it introduces fragmentation and increases operational overhead.
That's where Mastra comes in, it's is a TypeScript-based framework made specifically to address this layer of complexity.
Mastra does not replace existing infrastructure. Instead, it organizes how components (models, tools, memory, and workflows) interact, providing a consistent way to build and operate AI systems within a standard backend environment.
A structured layer on top of AI infrastructure
In a typical AI-powered software architecture setup, Mastra sits alongside your backend services.
A request flow in such a service might look like: user → API → workflow → agent → tools → data sources → response.
Mastra is designed to coordinate this request flow without requiring software engineering teams to orchestrate each step manually. Inside the framework, agents handle reasoning, workflows define execution logic, and tools connect the system to external services.
Mastra fits naturally into modern TypeScript and Node.js application stacks. Additionally, Mastra works well with frameworks such as Next.js, React, Express, or similar environments. Workflows can run using Mastra’s execution engine or be integrated into existing infrastructure and deployment pipelines.
Model abstraction and multi-provider flexibility
Mastra provides a unified interface for working with multiple LLM providers.
Instead of tightly coupling your system to a single vendor, you can integrate models from providers such as OpenAI, Anthropic, or others through a consistent abstraction layer. This multi-model feature lets engineering teams route requests based on context. For example, engineers can use lower-cost models for simple tasks and higher-capability models for more complex reasoning.
An approach like this also allows fallback strategies in case of provider issues and reduces long-term vendor lock-in. As systems scale, this flexibility becomes important for both cost control and reliability.
Connecting AI to real systems
By default, LLMs cannot interact with external systems. Mastra addresses this issue through tools.
Tools allow agents to:
- query databases;
- call internal or third-party APIs;
- execute business logic;
- trigger downstream workflows.
Tooling shifts AI systems from being purely conversational to being operational, capable of performing real tasks within an application.
Separating reasoning from control
A core pattern in Mastra is the distinction between agents and workflows.
Agents are responsible for interpretation and decision-making. They rely on LLMs to process input, decide which tools to use, and generate outputs, making them flexible, but inherently non-deterministic. Workflows on the other hand, provide structure. They define explicit execution paths, including sequencing, branching, retries, and state handling, thus making critical processes more predictable and easier to control.
In production setups, agents are often used within workflows. The workflow controls the process, while the agent handles reasoning within defined boundaries. This kind of separation is key for building systems that are both flexible and reliable.
Moreover, a new feature - workspaces (controlled execution environments) takes it one step further.
Workspaces provide controlled execution environments where agents can safely perform real actions, such as file operations, command execution, and data access, under defined permission boundaries. This new featurem for agent scenarios reduces the need for custom tooling while at the same time enabling fine-grained control through restrictions, approvals, and scoped capabilities.
Flexible memory
Mastra supports memory as a first-class concept, but it is not a one-size-fits-all feature.
Developers can implement:
- short-term (session-based) memory;
- long-term or persistent storage;
- semantic memory using vector search.
The framework provides structure, but decisions around storage, retrieval, and retention still need to be made based on the use case. This flexibility is useful, but it also means memory design is part of the system architecture, not just a configuration toggle.
RAG as a pattern
Mastra provides strong support for building retrieval-augmented generation (RAG) workflows.
A typical implementation involves retrieving relevant data, injecting it into the model context, and generating responses grounded in that information. Mastra helps orchestrate this flow, while storage, indexing, and retrieval mechanisms are handled by external systems.
With a process like this in place it is possible to integrate domain-specific knowledge, such as legal, financial, or operational data, into AI systems in a controlled and auditable way.
Reliability, error handling, and control
Production systems require predictable behavior, even when components fail.
Mastra workflows allow teams to implement:
- retries for failed steps;
- fallback logic (including switching models or tools);
- branching based on outcomes;
- conditional execution paths.
Workflows can also support pause-and-resume patterns, enabling human-in-the-loop interactions where manual validation is required before continuing execution.
Observability and evaluation
One of the challenges in AI systems is visibility.
Mastra helps with this issue by providing tools for:
- tracing agent execution;
- inspecting tool usage;
- understanding how outputs are generated.
All these processes are critical when debugging non-deterministic systems. Additionally, evaluation tools allow teams to compare outputs across versions, test prompt and workflow changes, as well as measure performance over time, and support a more iterative and controlled development process.
TypeScript-first development
Mastra is designed for teams already working in JavaScript and TypeScript environments. The design brings about several practical benefits:
- no need to adopt a new language or paradigm;
- strong typing for agents and workflows;
- easier integration with existing backend systems.
It also aligns well with modern web stacks, making it easier to embed AI capabilities into existing products.
Built to grow with your product
Mastra supports expansion as your needs evolve.
Its modular architecture allows teams to add new capabilities, scale agent systems, and handle increasing complexity without reworking the foundation.
Mastra is designed to support growth in both complexity and scale and is suitable for both early-stage and mature applications.
A modular approach allows:
- multiple agents working together (multi-agent systems);
- separation of concerns between logic, data, and execution;
- incremental addition of new tools and workflows.
As requirements evolve, teams can extend the system without rewriting core components.
Security and data handling
Mastra operates within your existing infrastructure, allowing teams to design data flows according to their own security and compliance requirements.
Sensitive data handling, storage choices, and access controls depend on implementation decisions. Combined with workflow control and tool restrictions, Mastra makes it easier for teams to define clear boundaries around how data is accessed, processed, and exposed to external services.
Cost and performance considerations
As AI systems scale, cost becomes a significant factor. Mastra’s architecture supports routing requests to different models based on task complexity, limiting unnecessary tool calls through workflow control, as well as structuring execution to reduce redundant LLM usage. These options allow teams to balance performance, cost, and accuracy without relying on a single model for all tasks.
Where Mastra fits best
Mastra is particularly useful for systems that require:
- multi-step reasoning;
- integration with multiple services;
- stateful interactions;
- repeatable and auditable workflows.
Examples include internal copilots, document processing pipelines, customer support automation, or data querying interfaces.
For simpler use cases, such as basic chat interfaces, using a direct LLM API may be sufficient.
Trade-offs and considerations
Mastra simplifies architecture, but it does not eliminate complexity entirely.
Teams should be aware of:
- The learning curve around workflows and orchestration;
- The need to design memory and data layers;
- Dependency on external model providers;
- The evolving nature of the ecosystem.
These are typical considerations for any modern AI system, but they remain relevant.
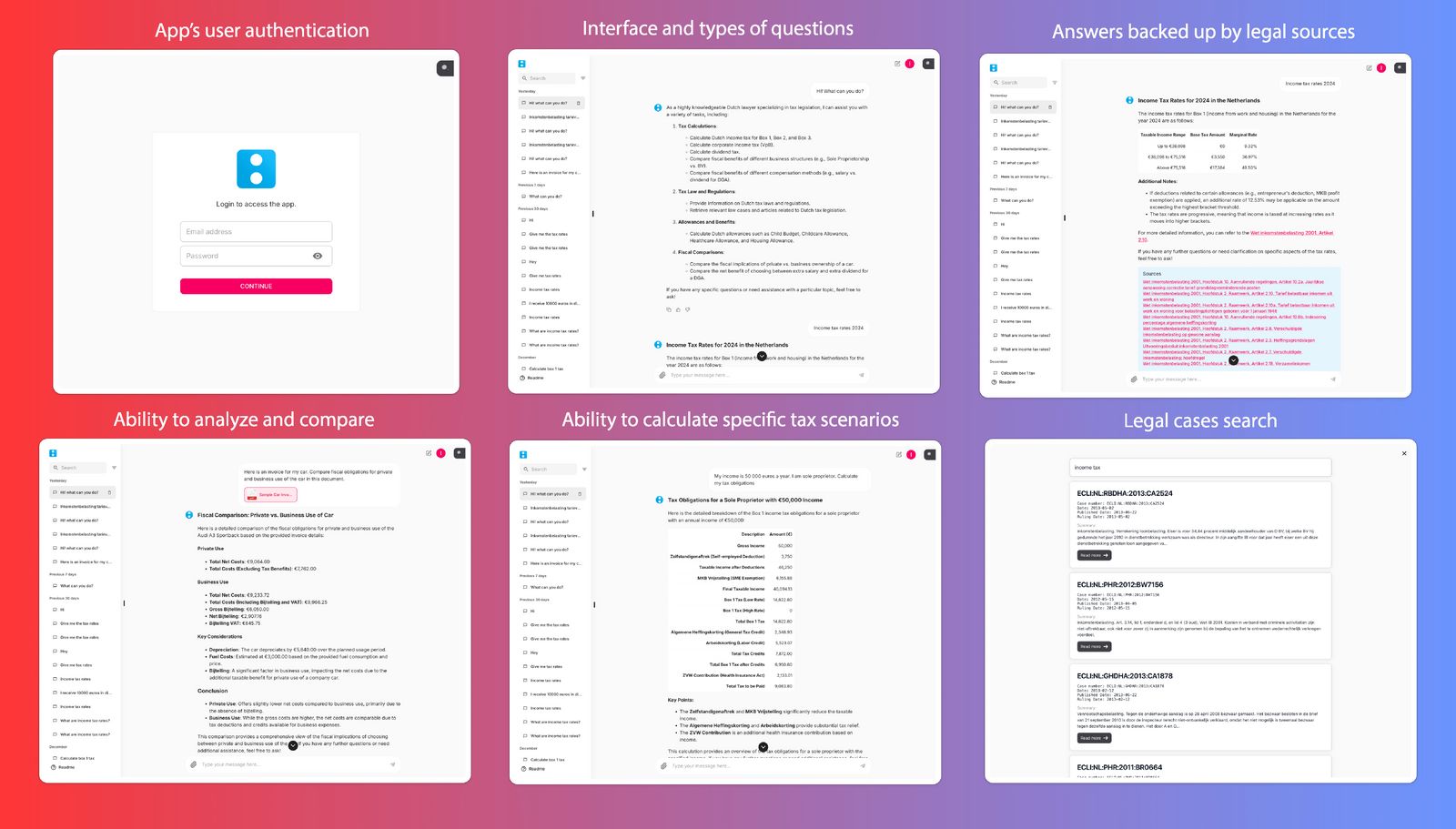
Learn how we helped our partners create a reliable AI solution with Mastra
Our team developed an AI-powered tax assistant focused on Dutch legislation, using Mastra to structure and orchestrate the system.
Mastra enabled us to build a solution capable of processing and analyzing documents across multiple formats, including PDFs, images, and spreadsheets, all while combining that data with structured workflows and domain-specific knowledge. The system can now perform complex tax calculations for scenario-based queries and return responses supported by relevant laws and legal cases.
For example, a user can upload a car purchase invoice and request a breakdown of fiscal obligations. The assistant evaluates the document, applies tax rules, and compares outcomes based on different usage scenarios, such as private versus commercial use.
Mastra’s workflow orchestration allows the system to reliably handle multi-step processes, document parsing, data extraction, rule application, and response generation, all within a single pipeline. Its support for tool integrations enables the assistant to query external data sources and legal databases in real time.
The solution also leverages retrieval-augmented generation (RAG), where the agent retrieves relevant legal texts and case law before generating a response. This ensures outputs are grounded in up-to-date regulations and provides users with verifiable references.
Mastra goes beyond simple Q&A by providing structured, context-aware tax assistance that scales and aligns with real-world legal requirements.
Final thoughts
Mastra provides a structured way to build AI systems that are maintainable, scalable, and closer to production requirements.
By separating agent reasoning from workflow control and integrating memory and tools into a unified model, it reduces the need for custom orchestration while keeping flexibility.
For teams building complex, AI-driven applications, it offers a practical framework that balances speed of development with system reliability.
If you're evaluating how to move from AI prototypes to production systems, Mastra is worth considering as part of your architecture.
